
Pandas와 Matplotlib를 이용한 데이터 시각화 예제 (세계 top10 인구 변화)
Pandas와 Matplotlib을 이용하여 세계 상위 10개국의 인구 변화를 line plot으로 시각화하는 예제를 만들어 보도록 하자.
시각화를 위해 jupyter notebook을 사용하였다.
0. 데이터 출처
세계 인구 데이터는 Kaggle에서 다운로드 받아서 사용할 수 있다.
1. 데이터 준비
import sys
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams.update(
{
"font.family": "AppleGothic" if sys.platform == "darwin" else "Malgun Gothic",
"font.size": 8,
"figure.figsize": (12, 6),
"axes.unicode_minus": False,
}
)
# 데이터의 경로는 상황에 맞게 변경
origin = pd.read_csv("./world_population_data.csv", index_col=0)
origin.head()
출력 결과 확인 (상위 5개)
| cca3 | country | continent | 2023 population | 2022 population | 2020 population | 2015 population | 2010 population | 2000 population | 1990 population | 1980 population | 1970 population | area (km²) | density (km²) | growth rate | world percentage | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| rank | ||||||||||||||||
| 1 | IND | India | Asia | 1428627663 | 1417173173 | 1396387127 | 1322866505 | 1240613620 | 1059633675 | 870452165 | 696828385 | 557501301 | 3287590.00 | 481 | 0.81% | 17.85% |
| 2 | CHN | China | Asia | 1425671352 | 1425887337 | 1424929781 | 1393715448 | 1348191368 | 1264099069 | 1153704252 | 982372466 | 822534450 | 9706961.00 | 151 | -0.02% | 17.81% |
| 3 | USA | United States | North America | 339996563 | 338289857 | 335942003 | 324607776 | 311182845 | 282398554 | 248083732 | 223140018 | 200328340 | 9372610.00 | 37 | 0.50% | 4.25% |
| 4 | IDN | Indonesia | Asia | 277534122 | 275501339 | 271857970 | 259091970 | 244016173 | 214072421 | 182159874 | 148177096 | 115228394 | 1904569.00 | 148 | 0.74% | 3.47% |
| 5 | PAK | Pakistan | Asia | 240485658 | 235824862 | 227196741 | 210969298 | 194454498 | 154369924 | 115414069 | 80624057 | 59290872 | 881912.00 | 312 | 1.98% | 3.00% |
234 rows × 16 columns
2. 데이터 전처리
상위 10개국의 데이터만 추출하고 연도의 컬럼을 reverse(반전) 시킨다.
# rank 순으로 이미 정렬이 되어있기 때문에 따로 처리 없이 인덱스를 cca3(국가코드)로 변경
df = origin.copy().head(10).set_index("cca3")
# 모든 컬럼 반전
df = df[df.columns[::-1]]
df
출력 결과 확인
| world percentage | growth rate | density (km²) | area (km²) | 1970 population | 1980 population | 1990 population | 2000 population | 2010 population | 2015 population | 2020 population | 2022 population | 2023 population | continent | country | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cca3 | |||||||||||||||
| IND | 17.85% | 0.81% | 481 | 3287590.0 | 557501301 | 696828385 | 870452165 | 1059633675 | 1240613620 | 1322866505 | 1396387127 | 1417173173 | 1428627663 | Asia | India |
| CHN | 17.81% | -0.02% | 151 | 9706961.0 | 822534450 | 982372466 | 1153704252 | 1264099069 | 1348191368 | 1393715448 | 1424929781 | 1425887337 | 1425671352 | Asia | China |
| USA | 4.25% | 0.50% | 37 | 9372610.0 | 200328340 | 223140018 | 248083732 | 282398554 | 311182845 | 324607776 | 335942003 | 338289857 | 339996563 | North America | United States |
| IDN | 3.47% | 0.74% | 148 | 1904569.0 | 115228394 | 148177096 | 182159874 | 214072421 | 244016173 | 259091970 | 271857970 | 275501339 | 277534122 | Asia | Indonesia |
| PAK | 3.00% | 1.98% | 312 | 881912.0 | 59290872 | 80624057 | 115414069 | 154369924 | 194454498 | 210969298 | 227196741 | 235824862 | 240485658 | Asia | Pakistan |
| NGA | 2.80% | 2.41% | 246 | 923768.0 | 55569264 | 72951439 | 95214257 | 122851984 | 160952853 | 183995785 | 208327405 | 218541212 | 223804632 | Africa | Nigeria |
| BRA | 2.70% | 0.52% | 26 | 8515767.0 | 96369875 | 122288383 | 150706446 | 175873720 | 196353492 | 205188205 | 213196304 | 215313498 | 216422446 | South America | Brazil |
| BGD | 2.16% | 1.03% | 1329 | 147570.0 | 67541860 | 83929765 | 107147651 | 129193327 | 148391139 | 157830000 | 167420951 | 171186372 | 172954319 | Asia | Bangladesh |
| RUS | 1.80% | -0.19% | 9 | 17098242.0 | 130093010 | 138257420 | 148005704 | 146844839 | 143242599 | 144668389 | 145617329 | 144713314 | 144444359 | Europe | Russia |
| MEX | 1.60% | 0.75% | 66 | 1964375.0 | 50289306 | 67705186 | 81720428 | 97873442 | 112532401 | 120149897 | 125998302 | 127504125 | 128455567 | North America | Mexico |
3. 데이터 시각화
# filter를 이용하여 컬럼명에 population이 포함된 컬럼만 추출한다.
# 속성 T는 transpose() 메서드에 대한 약어로 행과 열을 바꾼다.
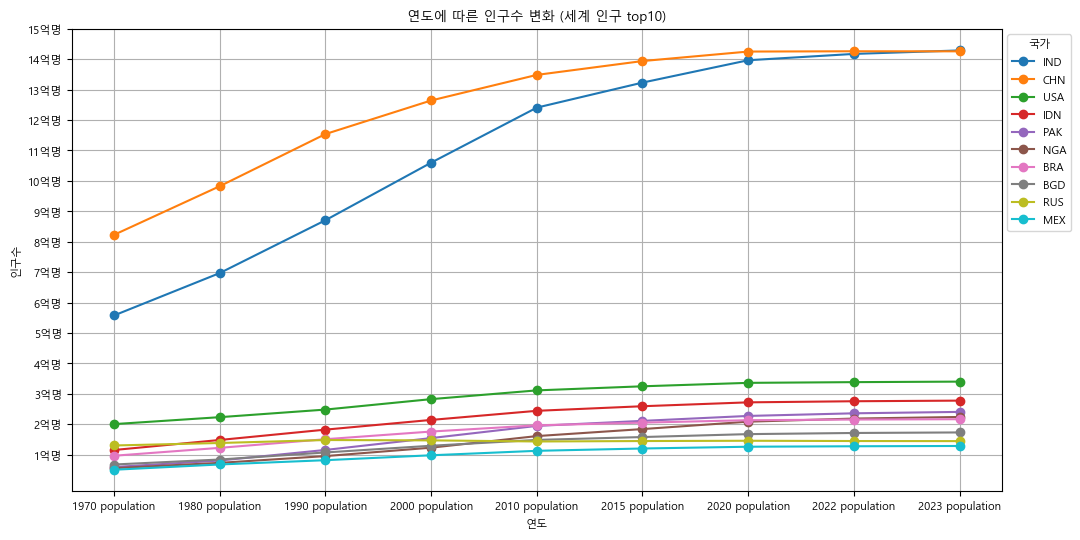
plt.plot(df.filter(like="population").T, marker="o", label=df.index)
# 그래프의 제목
plt.title("연도에 따른 인구수 변화 (세계 인구 top10)")
# x축 라벨
plt.xlabel("연도")
# y축 라벨
plt.ylabel("인구수")
# y축 눈금 설정 (1e8은 1억을 의미하고 이를 15번 반복하면서 15억까지 표시한다.)
plt.yticks([1e8 * i for i in range(1, 16)], [f"{i}억명" for i in range(1, 16)])
# 그리드 표시
plt.grid()
# 범례 표시
plt.legend(title="국가", loc="upper left", bbox_to_anchor=(1, 1))
# 그래프 출력
plt.show()
plt.close()
출력 결과 확인
4. 최종 코드
import sys
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams.update(
{
"font.family": "AppleGothic" if sys.platform == "darwin" else "Malgun Gothic",
"font.size": 8,
"figure.figsize": (12, 6),
"axes.unicode_minus": False,
}
)
origin = pd.read_csv("./world_population_data.csv", index_col=0)
df = origin.copy().head(10).set_index("cca3")
df = df[df.columns[::-1]]
plt.plot(df.filter(like="population").T, marker="o", label=df.index)
plt.title("연도에 따른 인구수 변화 (세계 인구 top10)")
plt.xlabel("연도")
plt.ylabel("인구수")
plt.yticks([1e8 * i for i in range(1, 16)], [f"{i}억명" for i in range(1, 16)])
plt.grid()
plt.legend(title="국가", loc="upper left", bbox_to_anchor=(1, 1))
plt.show()
plt.close()




Leave a comment